Insights into data
Graph Website Links With Neo4j
There are many tools to use to capture your site’s structure. ScreamingFrog SEO Crawler is a vital tool for SEOs and is extremely easy to get setup and export data. It can help you find broken links, review title and meta descriptions, evaluate redirects, etc… All and all, a useful tool to evaluate a site from an SEO perspective.
However, viewing the site as a graph can give you a visualization of your site’s structure, and if the visualization of your site’s structure doesn’t match up with what you thought it would be, then you could dig deeper.
For this post, I wanted to get a visualization of a site’s internal link structure. I used ScreamingFrog SEO Crawler to get the links for a website and Neo4j to graph the internal links.
The following image is of the internal links of the site I crawled. The blue circles are web pages, the yellow circles are CSS files, the green circles are javascript files, and the purple circles are images.
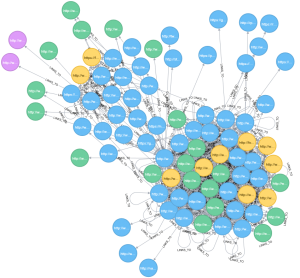
Export Internal Links
You can download the SEO Crawler Tool from their site. The install is straight forward, and after the install, start it up.
- For the Enter url to spider input, type www.justinnafe.com.
- Click Start
- Once complete, in the menu bar, click on Bulk Export and select All Inlinks to download.
- Make note of the path you downloaded it to.
Import Website Links to Neo4j
I was unable to use load csv with header because the seo frog tool adds an unnecessary line on line one. Using LOAD CSV and the array with a WHERE clause, I can skip over the lines that I don’t need when importing data with Neo4j.
If copying and pasting the code, be sure to replace the file path. Also, if you have spaces in the file path, be sure to replace them with %20
LOAD CSV FROM "file:///C:/filepath/all_inlinks.csv" AS row
WITH row[0] AS Type, row[1] AS Source, row[2] AS Destination, COALESCE(row[3], "NA") AS AltText,
COALESCE(row[4], "NA") AS Anchor, row[5] AS StatusCode, row[6] AS Status, COALESCE(row[7], "NA") AS Follow
WHERE NOT Type CONTAINS 'All Inlinks' AND NOT Type CONTAINS 'Type'
MERGE (s:WebResource {name: Source})
MERGE (d:WebResource {name: Destination})
MERGE (s)-[:LINKS_TO {type: Type, altText: AltText,
anchorText: Anchor, statusCode: StatusCode, status: Status,
follow: Follow}]->(d)
Label the nodes to the different types of pages, for visualization and querying.
MATCH (s)-[r:LINKS_TO {type: 'IMG'}]->(d)
SET d :Img
RETURN d
MATCH (s)-[r:LINKS_TO {type: 'JS'}]->(d)
SET d :Js
RETURN d
MATCH (s)-[r:LINKS_TO {type: 'HREF'}]->(d)
SET d :WebPage
SET s :WebPage
RETURN d, s
MATCH (s)-[r:LINKS_TO {type: 'CSS'}]->(d)
SET d :Css
RETURN d
Visualize the site
MATCH (s)-[r]->(d) RETURN s, r, d
The type WebPage nodes should always be a page, so how many pages (internal or external)?
MATCH (w:WebPage) RETURN COUNT(w) AS `Page Count`
| Page Count |
|---|
| 53 |
How many internal pages?
MATCH (w:WebPage) WHERE w.name CONTAINS 'justinnafe.com' RETURN COUNT(w) AS `Internal Pages`
| Internal Pages |
|---|
| 37 |
How many links to pages (internal or external)?
MATCH (s:WebPage)-[r:LINKS_TO]->(d:WebPage) RETURN COUNT(r) AS `Links to Pages`
| Links to Pages |
|---|
| 426 |
How many links to external pages (pages outside of the domain)?
MATCH (s:WebPage)-[r:LINKS_TO]->(d:WebPage) WHERE NOT d.name CONTAINS 'justinnafe.com' RETURN COUNT(r) AS `Links to External Pages`
| Links to External Pages |
|---|
| 67 |
How many links to internal pages. All pages in the source column are pages on the site, so we need to check the destination for the name not containing or containing the domain name.
MATCH (s:WebPage)-[r:LINKS_TO]->(d:WebPage) WHERE d.name CONTAINS 'justinnafe.com' RETURN COUNT(r) AS `Links to Internal Pages`
| Links to Internal Pages |
|---|
| 359 |
How many links per page?
MATCH (s:WebPage)-[r:LINKS_TO]->(d:WebPage) RETURN s.name AS Page, COUNT(r) AS NumLinks ORDER BY NumLinks DESC
| Page | NumLinks |
|---|---|
| http://www.justinnafe.com/author/justinnafe/ | 41 |
| http://www.justinnafe.com/data-science/crimes-per-zip-code-in-dallas-2014/ | 22 |
| http://www.justinnafe.com/category/data-science/ | 22 |
| http://www.justinnafe.com/data-science/crimes-per-hour-in-dallas-texas-2014/ | 21 |
| http://www.justinnafe.com/html5/convert-html4-site-to-html5/ | 20 |
| http://www.justinnafe.com/natural-language-processing/dynamic-and-automatic-lexicon-generation-for-sentiment-analysis-in-the-business-domain/ | 19 |
| http://www.justinnafe.com/natural-language-processing/stock-market-polarity-extraction/ | 19 |
| http://www.justinnafe.com/data-science/introduction-to-data-science/ | 19 |
| http://www.justinnafe.com/technical-writing/organizational-information/ | 18 |
| http://www.justinnafe.com/ | 18 |
| http://www.justinnafe.com/wordpress/change-theme-template-in-wordpress/ | 18 |
| http://www.justinnafe.com/asterisk/setup-asterisk-to-use-smtp-with-auth/ | 18 |
| http://www.justinnafe.com/voip-security/voip-security/ | 18 |
| http://www.justinnafe.com/category/natural-language-processing/ | 18 |
| http://www.justinnafe.com/category/asterisk/ | 16 |
| http://www.justinnafe.com/category/html5/ | 16 |
| http://www.justinnafe.com/category/wordpress/ | 16 |
| http://www.justinnafe.com/category/computer-security/ | 16 |
| http://www.justinnafe.com/category/voip-security/ | 16 |
| http://www.justinnafe.com/category/technical-writing/ | 15 |
How many pages link to themselves, or what type of pages create this loop?
MATCH (n:WebPage)-[r]->(n) RETURN n, r
The image below, doesn’t clearly indicate the type of pages, but clicking on each node within Neo4j gives you more details about the node, and the type of pages that create this loop are Category and tag pages.
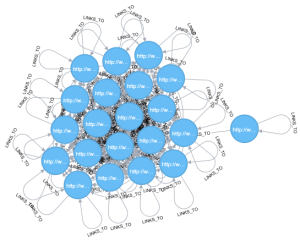
I also found that most of the posts contain a link to themselves around the date and the link is not clickable I’ll need to look into why that is there and if wordpress or the current theme adds it, then decide to remove it or not.
How many leaf pages (nodes with no links out)?
MATCH (s:WebPage)-[r:LINKS_TO]->(d:WebPage) WHERE not ((d)-->()) AND d.name CONTAINS 'justinnafe.com' RETURN d
The results are all pdf pages, which is fine.
Find diameter, or the depth of the site from the home page.
MATCH (n:WebPage {name: "http://www.justinnafe.com/"}), (m:WebPage)
WHERE n <> m
WITH n, m
MATCH p=shortestPath((n)-[*]->(m))
RETURN n.name AS `Home Page`, m.name AS `Destination Page`, length(p) AS Diameter
ORDER BY Diameter DESC LIMIT 1
| Home Page | Destination Page | Diameter |
|---|---|---|
| http://www.justinnafe.com/ | http://www.justinnafe.com/wp-login.php?redirect_to=http%3A%2F%2Fwww.justinnafe.com%2Fnatural-language-processing%2Fstock-market-polarity-extraction%2F | 3 |
How many orphaned pages (nodes with no links to)?
If you have a list of URLs that you would expect to see, then you can import that list to the SEO Spider by changing the mode from Spider to List and uploading the list of URLs. Since the spider data that we are using only tracks links to and from, you could find the orphaned pages by first loading the WebPage data from the expected list, then load the spider data. You may be able to find the orphaned pages with the following untested code.
MATCH (n) WHERE NOT (n)-[*]-() RETURN n
I’m sure that there are many other ways to import link data to Neo4j and would be interested in seeing more examples and interesting queries!
Justin Nafe May 15th, 2016
Posted In: Visualizations
Tags: graphs