Insights into data
Data Science Process
When working with data science on a regular basis within an organization, or for multiple organizations, a data science process is essential for creating quality analysis, insights, and models in an efficient manner.
The idea of having a standardized process for Data Science in particular is a somewhat new idea. For example, data science is often a team or individual who gathers data, processes the data, and generates a report for the business, often times different than the last report. This inconsistency makes it difficult to manage existing solutions and difficult for other team members to fill in.
Solutions
There are some concepts out there that are adopted by data scientists or team. Some of them are very general, which give a company a good starting point since most companies are not the same or use the same tools.
Data science often starts with a question and it helps to have an understanding of the business domain, or having domain knowledge.
We can take some ideas from Computer Science. Computer Science has a long history of having a process from conception to deployment. Some of those concepts are used here, such as SCRUM and sprints, having the code and data available to other team members.
In general, most processes focus on
- Gain Domain knowledge
- Access the data
- Explore the data
- Clean the data
- Create model
- Evaluate model
- Rinse and repeat
- Deploy
Microsoft’s Team Data Science Process
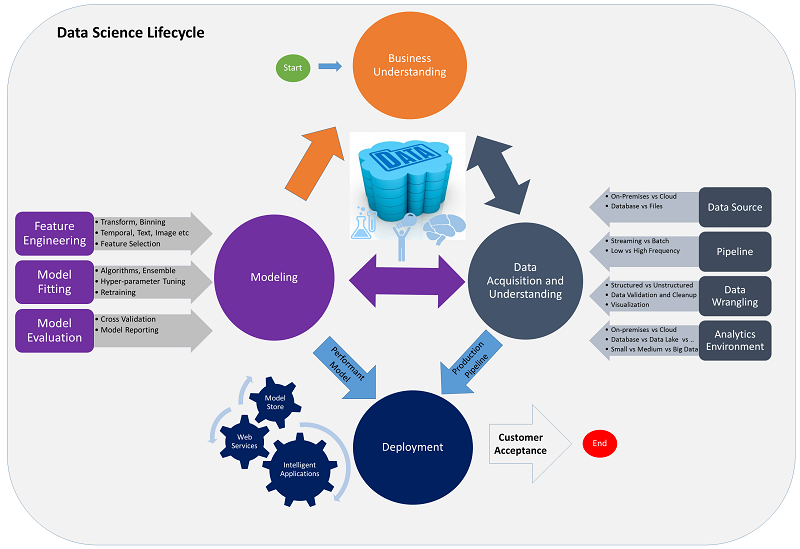
Since I am used to working in a .NET world and working within Team Foundation, I take a liking to Microsoft’s attempt at standardizing the data science process with Team Data Science Process (Brad Severtson 2016).
They use Team Foundation to build sprints, link their backlog items to the code they use to explore data or generate models. A bit more complex, and not as general as the other concepts, but there’s no hard set rule that you have to abide by every step of their process; however, if you are used to working within the environments they outline, it is a good starting point and the method seems less complex.
Cross Industry Standard Process for Data Mining (CRISP-DM)
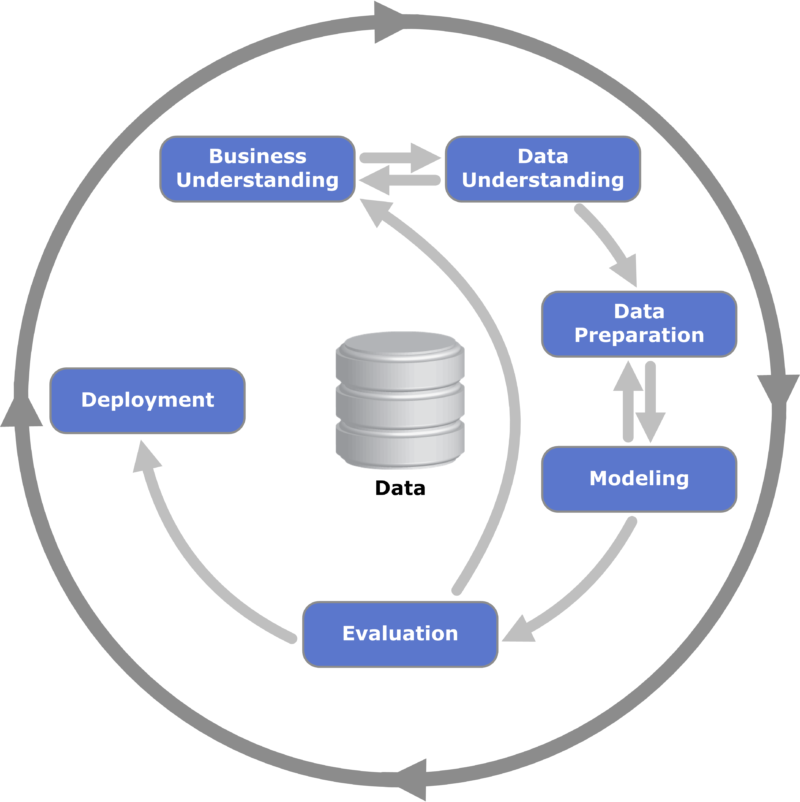
By Kenneth Jensen – Own work, CC BY-SA 3.0, Link
CRISP-DM is a general process for which to mine data and can be applied to Data Science process with 6 major phases (2016):
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
CRISP-DM lacks templates and guidelines, which are often helpful for use within teams and efficiency. The good news is that IBM revisited CRISP-DM and developed an alternative that addressed some of the CRISP-DM shortcomings. The project is called Analytics Solutions Unified Method for Data Mining/Predictive Analytics (ASUM-DM) (Jason Haffar 2015).
Guerrilla Analytics
In Enda Ridge’s book Guerrilla Analytics: A Practical Approach to Working with Data, he describes 7 principles to work with data.
- Principle 1: Space is cheap, confusion is expensive
- Principle 2: Prefer simple, visual project structures and conventions
- Principle 3: Prefer automation with program code
- Principle 4: Maintain a link between data on the file system, data in the analytics environment, and data in work products
- Principle 5: Version control changes to data and analytics code
- Principle 6: Consolidate team knowledge in version-controlled builds
- Principle 7: Prefer analytics code that runs from start to finish
(Ridge 2016)
Though I have not read the book yet, he does mention the importance of version control and other Computer Science practices, such as iterative development using Agile or Scrum.
Summary
Of course, you can extract certain concepts from each method, such as using an agile/scrum development process, version control, and templates to generate consistent reports at each stage of the data science process. For example, every data science project requires one to gather data, explore the data, clean and wrangle data, build and evaluate a model and make predictions. So likely the backlog items within the agile development process for a project would look something like:
- Data Ingestions (gather data, explore data)
- Data Transformation (with what was learned in the exploration, you could have a long list of possible transformations that could improve your model)
- Build and evaluate models (a variety of models could and should be used, along with evaluating the performance metric and overfitting)
- Deploy (specify the architecture used, data and model updates, etc…)
I prefer to use git for version control, and templates and checklists help improve efficiency, accuracy, consistency. Templates and checklists also help team members complete tasks.
One important aspect of having a process is that it builds confidence in one’s ability to efficiently produce quality content.
References
Brad Severtson, Larry Franks, Gary Ericson. 2016. “Team Data Science Process Lifecycle.” https://docs.microsoft.com/en-us/azure/machine-learning/data-science-process-overview.
Jason Haffar. 2015. “Have You Seen ASUM-DM?” https://developer.ibm.com/predictiveanalytics/2015/10/16/have-you-seen-asum-dm/.
Ridge, Enda. 2016. “The 7 Principles – Guerrilla Analytics.” http://guerrilla-analytics.net/the-principles/.
Justin Nafe December 27th, 2016
Posted In: Machine Learning
Tags: data science